-官方认证诚信至上 | 工业机器人及工控系统领军企业


NEWS
新闻资讯
为机器人开发赋能,RK3576环视方案解析
发布时间:
2025-12-13 13:30:48
来源:
浏览量:195
【导语】本文以米尔电子MYD-LR3576开发板为测试平台,其搭载的瑞芯微RK3576芯片算力强劲。经实际测试,该平台成功实现标准360环视处理流程,验证了功能可行性。性能实测显示,纯CPU方案难达实时标准,GPU方案潜力大但稳定性存挑战。若GPU性能稳定,其异构计算架构可让平台在完成环视合成的同时集成AI感知预警功能,有望升级为高附加值智能视觉平台。
一、项目背景与测试平台
本次360环视系统原型基于米尔电子MYD-LR3576开发板进行构建与评估。该开发板所搭载的瑞芯微RK3576芯片,集成了4核Cortex-A72、4核Cortex-A53、Mali-G52 GPU及高达6TOPS算力的NPU。本文旨在通过实际测试数据,从功能实现、实时性能与AI拓展潜力三大核心维度,为客户提供一份关于该平台在360环视应用中能力的真实参考。
二、系统流程与功能实现
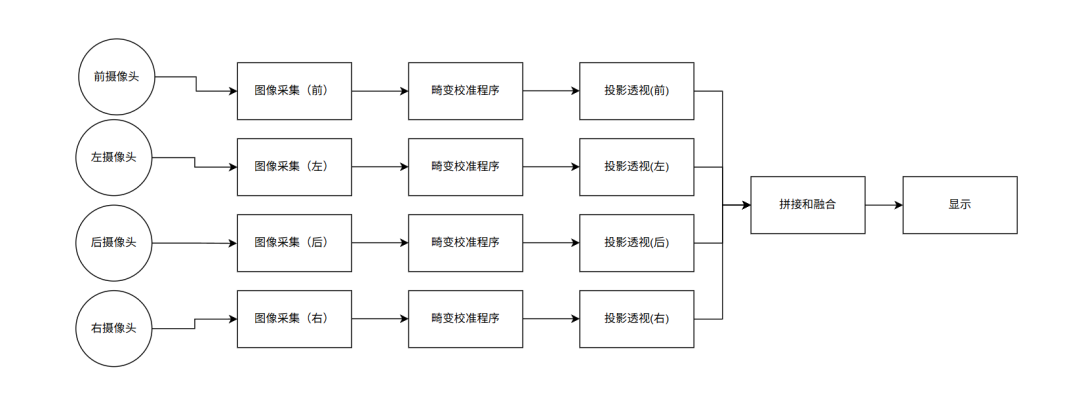
程序流程图
一套标准的360环视处理流水线已在开发板上成功实现,验证了其功能可行性:
1.传感器配置:4路720P分(fēn)辨(biàn)率(lǜ)鱼(yú)眼(yǎn)摄(shè)像(xiàng)头(tóu),精(jīng)确(què)固(gù)定(dìng)于(yú)模(mó)拟(nǐ)车(chē)辆(liàng)的(de)四(sì)周(zhōu)。
2.核(hé)心(xīn)处(chù)理(lǐ)流(liú)水(shuǐ)线(xiàn):
畸变矫正:利用张正友标定法预先获取摄像头内参和畸变系数,实时消除鱼眼镜头产生的图像扭曲。
投影变换:通过(guò)预(yù)设(shè)的(de)单(dān)应(yīng)性(xìng)矩(ju)阵(zhèn)(Homography Matrix),将(jiāng)矫(jiǎo)正(zhèng)后(hòu)的(de)透(tòu)视(shì)图(tú)像(xiàng)转(zhuǎn)换(huàn)为(wèi)统(tǒng)一(yī)的(de)俯(fǔ)瞰(kàn)视(shì)角(jiǎo)鸟(niǎo)瞰(kàn)图(tú)。
图像拼接:依据预先标定的位置关系,将四张鸟瞰图无缝合成为一张完整的360°全景俯视图。
显示:为快速验证核心流程,目前采用OpenCVimshow函数进行结果显示,已知其效率非最优,后续将优化为DRM/KMS等低延迟工业级方案。
畸变矫正前:

畸变矫正后:

投影视图:

图像拼接效果:

360环视视频效果演示:
三、性能实测:CPU与GPU的算力博弈
性能是决定方案能否商用的关键。我们以行业通用(yòng)的(de)25fps(即每帧处理间隔40ms)作为实时性标准,在米尔MYD-LR3576开发板上对数据处理管线进行了精细的性能剖析,关键数据对比如(rú)下(xià):

图:CPU负载情况
图:GPU负载情况
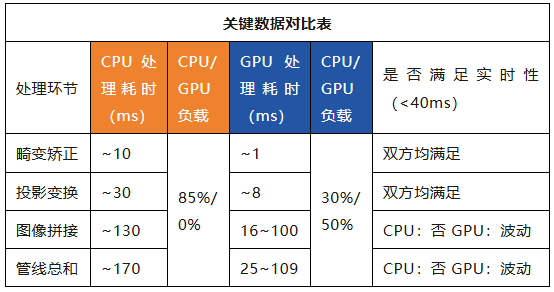
深度性能分析:
CPU方案:功能完整,但实时性无望
如上表数据所示,当所有处理任务均由CPU承担时,总耗时高达170ms,远超40ms的预算。其中,计算密集型的图像拼接成为绝对的性能瓶颈,几乎占满了所有A72大核的资源。这不仅导致系统无法实时处理视频流,造成严重卡顿和延迟,也使得CPU再无余力处理其他系统任务,此方案不具备产品化价值。
GPU方(fāng)案(àn):潜(qián)力(lì)巨大,稳定性是当前关键瓶颈
卓越的算力体现:在畸变矫正和投影变换环节,Mali-G52 GPU展现了其强大的并行计算能力,耗时相比CPU降低了数倍至一个数量级,且占用率较低,证明其处理此类像素级操作的高效性。
拼接环节的性能波动:图像拼接的耗时在16ms到100ms之间剧烈波动,这是阻碍当前方案投入实用的核心问题。GPU占用率的相应大幅变动,暗示了问题根源。
根因推测与进展:这种波动极有可能源于GPU内部的内存管理机制,如图像数据在显存中的频繁拷贝、同步等待或驱动调度开销。我们已将此性能波动问题作为高优先级案例提交给瑞芯微原厂技术支持。若能通过驱动或底层优化将拼接时间稳定在16ms的理想区间,则整个GPU处理管线可在25ms内完成,完全满足一帧内的处理需求。
四、未来拓展:释放NPU算力,实现从“看到”到“理解”的飞跃
当GPU处理管线优化完成后,我们将获得一个极具吸引力的系统状态:充裕的时间预算和富余的CPU资源。这为集成更高价值的AI功能奠定了坚实基础。
剩余时间预算分析:
在25fps帧率下,系统必须在40ms内完成一帧的所有处理。假设GPU流水线稳定在25ms完成环视基础处理,那么系统还剩下约15ms的时间裕度。
NPU的用武之地:
这15ms的宝贵时间,正是留给RK3576内置的6TOPS NPU大显身手的舞台。我们可以利用这部分算力,在环视全景图或原始鱼眼图上并行运行轻量化的AI模型,实现功能的全面升级,例如:
障碍物检测与识别:精准识别车辆周围的行人、车辆、锥桶等障碍物。
空间距离估算:基于俯视图的几何关系,实时计算识别出的物体与车身的精确距离。
主动预警系统:当距离低于安全阈值时,立即触发声音或视觉警报,实现真正的主动安全功能。
总结与展望

米尔MYD-LR3576开发板
功能实现:基于米尔MYD-LR3576开发板的RK3576平台完全具备实现高质量360环视全链路功能的能力。
实时性能:纯CPU方案无法满足25fps实时需求。GPU方案拥有足够的算力潜力,但其执行的稳定性是当前能否商用的关键挑战。
方案潜力与价值:一旦GPU性能稳定,RK3576凭借其异构计算架构(CPU+GPU+NPU),能够在一帧时间内不仅完成环视合成,更能集成复杂的AI感知与预警功能。这使其从一个单纯的环视处理器,升级为一个高集成度、高附加值的智能视觉平台。
ONLINE MESSAGE
在线留言
*注:请务必信息填写准确,并保持通讯畅通,我们会尽快与你取得联系


上海智能机器人科技股份有限公司
Shanghai United Intelligence Robotics Inc.
产品咨询: sale@jinnian.com
其他业务: service@jinnian.com
销售热线:400-65738829-8071
邮寄地址:上海市浦东新区申迪南路80号5楼
一 子公司 一
智能机器人(浙江)有限公司
United Intelligence Robotics (Zhejiang) Co.,Ltd
电子邮箱: e-mail@jinnian.com
业务咨询: contact@jinnian.com
销售热线:0755-25836555
万维网址: www.ybgsyj.com
邮寄地址: 浙江省杭州市滨江区长河街道网商路586号6幢3层

扫码手机查看