-官方认证诚信至上 | 工业机器人及工控系统领军企业


NEWS
新闻资讯
利用NVIDIA Cosmos模型训练通用机器人
发布时间:
2025-08-05 18:31:28
来源:
浏览量:330
【导语】机器人领域面临的一大核心挑战在于如何高效掌握新任务,无需针对每项任务和环境大量收集与标注数据集。NVIDIA最新研究通过生成式AI、世界基础模型(如NVIDIA Cosmos)及数据生成蓝图(如Isaac GR00T-Mimic与GR00T-Dreams)等创新方案,成功突破这一瓶颈。本期NVIDIA机器人研究与开发摘要(R²D²)将深(shēn)入(rù)介(jiè)绍(shào)如何利用世界基础模型实现可扩展的合成数据生成与机器人模型训练工作流,包括DreamGen、GR00T N1等关键技术,以及通过视频进行潜在动作预训练和仿真与现实协同训练等先进方法。这些技术不仅加速了机器人的学习过程,还显著提升了模型的鲁棒性和适应性,为机器人领域的未来发展开辟了广阔前景。
机器人领域的一大核心挑战(zhàn)在(zài)于(yú)如(rú)何(hé)让(ràng)机(jī)器(qì)人(rén)掌(zhǎng)握(wò)新(xīn)任(rèn)务(wu),而(ér)无(wú)需(xū)针(zhēn)对(duì)每(měi)个(gè)新(xīn)任(rèn)务(wu)和(hé)环(huán)境(jìng)耗(hào)费(fèi)大(dà)量(liàng)精(jīng)力(lì)收(shōu)集和(hé)标(biāo)注(zhù)数(shù)据(jù)集。NVIDIA 的(de)最(zuì)新(xīn)研(yán)究(jiū)方(fāng)案(àn)通(tōng)过(guò)生(shēng)成(chéng)式(shì) AI、世(shì)界(jiè)基(jī)础模型(如NVIDIA Cosmos)以及数据生成蓝图(如Isaac GR00T-Mimic与GR00T-Dreams)来克服这一挑战。
本期 NVIDIA 机器人研究与开发摘要 (R²D²) 将介绍如何通过世界基础模型实现可扩展的合成数据生成与机器人模型训练工作流,具体包括:
DreamGen:Isaac GR00T-Dreams blueprint的研究基础。
GR00T N1:开源基础模型,使机器人能够通过真实数据、人类演示和合成数据学习跨任务与形态的通用技能。
通过视频进行潜在动作预训练:无监督的学习方法,无需人工动作标注,就能从大规模视频中学习机器人相关动作。
仿真与现实协同训练:结合仿真环境与真实世界机器人数据的训练方法,可构建更具鲁棒性和适应性的机器人策略。
机器人世界基础模型
NVIDIA Cosmos 世界基础模型经过数百万小时真实世界数据训练,能够预测未来世界状态,并基于单张输入图像生成视频序列。这项技术使机器人和自动驾驶车辆具备预判未来事件的能力,这种预测能力对于合成数据生成流程至关重要,有助于快速创建多样化、高保真的训练数据。这一方法大幅加速了机器人的学习过程,提升了模型的鲁棒性,并将原本需要数月人工投入的开发时间缩短至仅数小时。
DreamGen
DreamGen 是一种合成(chéng)数(shù)据(jù)生(shēng)成(chéng)流程。机器人学习需要收集大规模人类远程操作数据,成本高昂且耗费人力,而 DreamGen 就有助于解决这一问题,它是 Isaac GR00T-Dreams 的基础,这一蓝图可借助世界基础模型生成海量的合成机器人轨迹数据。
传统的机器人基础模型在面对每一项新任务和新环境时,都需要大量人工演示,这种方式不具备可扩展性。而基于仿真的替代方案则经(jīng)常受到“仿真到现实”差距的困扰,且需要大量人工工程投入。
DreamGen 通过世界基础模型突破这些限制,仅需极少量人工干预即可生成高真实性、多样化的训练数据。该方法实现了机器人学习的规模化扩展,并能在不同行为模式、环境场景及机器人形态间实现泛化。
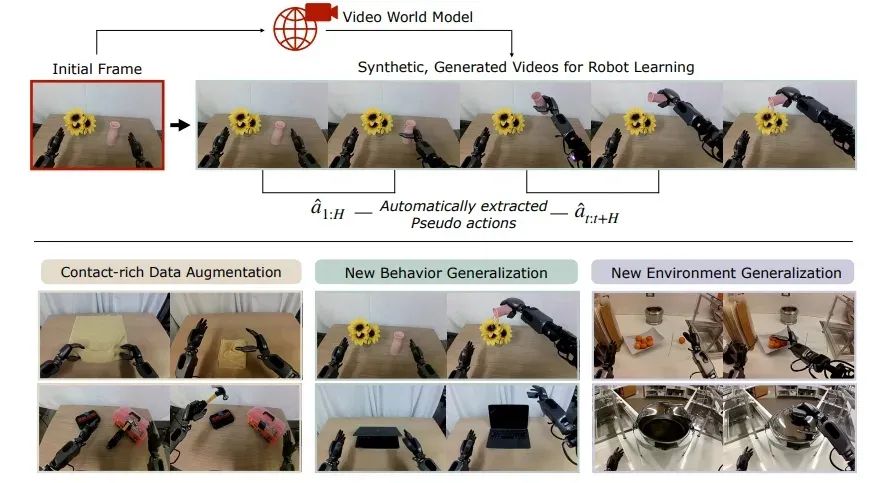
图 1. 通过 DreamGen 实现泛化
DreamGen 技术流程包含四个核心步骤:
1. 世界基础模型的后训练:
利用少量真实演示数据,将Cosmos-Predict2等世界基(jī)础(chǔ)模(mó)型(xíng)适(shì)配(pèi)至(zhì)目(mù)标(biāo)机(jī)器(qì)人(rén)。Cosmos-Predict2 能(néng)够(gòu)通(tōng)过(guò)文本(běn)生(shēng)成(chéng)高(gāo)质(zhì)量(liàng)图(tú)像(xiàng)(文本(běn)到(dào)图像),并通过图像或视频生成视觉仿真内容(视频到世界)。
2. 生成合成视频:
基于经过后训练的模型,通过图像和语言提示,为新任务与新环境创建多样化、逼真的机器人视频。
3. 提取伪动作:
应用潜在动作模型或逆动力学模型 (IDM),将这些视频转换为带标签的动作序列(神经轨迹)。
4. 训练机器人策略:
利用生成的合成轨迹训练视觉运动策略,使机器人能够执行新行为,并能泛化至未见过的场景。
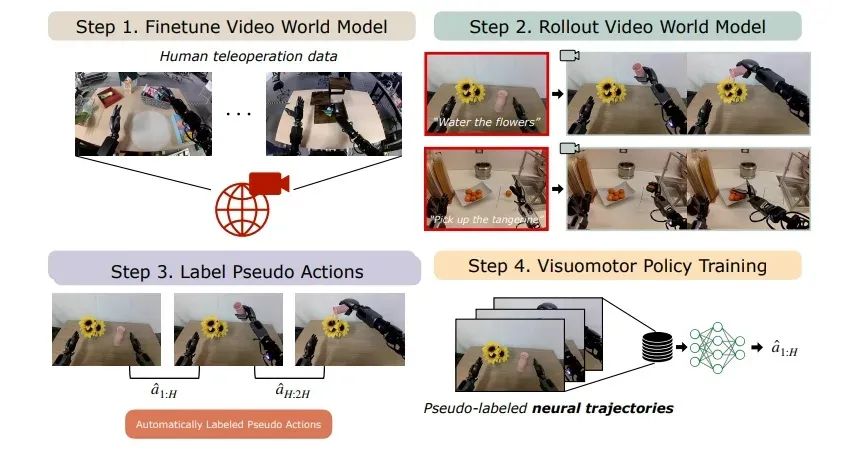
图 2. DreamGen 工作流概览
DreamGen Bench
DreamGen Bench 是一个专门设计的基准测试,用于评估视频生成模型在适配特定机器人形态时的效果,同时考察这些模型对刚体物理规律的内化程度,以及向新物体、新行为和新环境的泛化能力。该基准测试对四个领先的世界基础模型进行(xíng)测(cè)试(shì),分(fēn)别(bié)是(shì) NVIDIA Cosmos、WAN 2.1、混元和 CogVideoX,并衡量两项关键指标:
指令遵循:评估生成视频是否准确反映任务指令(如"拿起洋葱"),采用 Qwen-VL-2.5 等视觉语言模型和人工标注进行双重验证。
物理规律(lǜ)遵(zūn)循(xún):通(tōng)过(guò) VideoCon-Physics 和(hé) Qwen-VL-2.5 等(děng)工(gōng)具(jù)量(liàng)化(huà)物(wù)理(lǐ)真(zhēn)实(shí)性(xìng),确(què)保(bǎo)视(shì)频(pín)符(fú)合真实世界物理规律。
如图 3 所示,我们发现,在 DreamGen 基准测试中得分较高的模型(即能够生成更真实且符合指令的合成数据的模型),在用于机器人真实操作任务的训练和测试时,也有更优的性能表现。这种正相关关系表明,投入研发更强大的世界基础模型,不仅能提升合成训练数据的质量,还能直接转化为实际应用中能力更强、适应性更优的机器人。
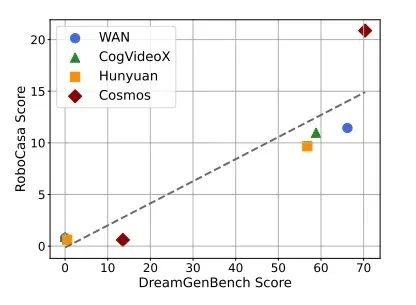
图 3. DreamGen Bench 与 RoboCasa 之间的性能正相关
Isaac GR00T-Dreams
基于 DreamGen 研究的 Isaac GR00T-Dreams,是一套用于生成大规模机器人动作合成轨迹数据集的工作流。这些数据集可用于实体机器人的训练,与收集真实世界动作数据相比,能节省大量时间和人力投入。
GR00T-Dreams 借助 Cosmos Predict2 世界基础模型和Cosmos Reason来为不同任务和环境生成(chéng)数(shù)据(jù)。Cosmos Reason 模(mó)型(xíng)包(bāo)含(hán)多(duō)模(mó)态(tài)大(dà)型(xíng)语(yǔ)言(yán)模(mó)型(xíng),能(néng)针(zhēn)对(duì)用(yòng)户(hù)提(tí)示(shì)生(shēng)成(chéng)基(jī)于(yú)物(wù)理(lǐ)原(yuán)理(lǐ)的(de)响(xiǎng)应(yīng)。
通(tōng)用(yòng)机(jī)器(qì)人(rén)训(xun)练(liàn)模(mó)型与工作流
视觉语言动作 (VLA) 模型可以通过世界基础模型生成的数据进行后训练,从而在未知环境中实现新的行为和操作。
NVIDIA 研究中心使用 GR00T-Dreams blueprint 生成合成训练数据,仅用 36 小时就开发出了GR00T N1的升级版本GR00T N1.5。如果采用人工收集数据的方式,这个过程需要近三个月时间。
GR00T N1 是全球首个面向通用人形机器人的开源基础模型,标志(zhì)着(zhe)机器人和 AI 领域的重大突破(pò)。该(gāi)模(mó)型(xíng)采用(yòng)受(shòu)人(rén)类(lèi)认(rèn)知(zhī)启(qǐ)发(fā)的(de)双(shuāng)系(xì)统(tǒng)架(jià)构(gòu),统(tǒng)一(yī)了(le)视(shì)觉(jué)、语(yǔ)言(yán)和(hé)动(dòng)作(zuò),使(shǐ)机(jī)器(qì)人(rén)能(néng)够(gòu)理(lǐ)解(jiě)指(zhǐ)令(lìng)、感(gǎn)知(zhī)环(huán)境(jìng)并(bìng)执(zhí)行(xíng)复(fù)杂(zá)的(de)多(duō)步(bù)骤(zhòu)任(rèn)务(wu)。
GR00T N1 以(yǐ)通(tōng)过(guò)视频进行潜在动作预训练 (LAPA) 等技术为基础,能够从无标签的人类视频中学习,同时它还采用了仿真与现实协同训练等方法,通过融合合成数据与真实世界数据来增强模(mó)型(xíng)的(de)泛(fàn)化(huà)能(néng)力(lì)。本(běn)文后(hòu)续(xù)将(jiāng)详(xiáng)细(xì)介(jiè)绍(shào) LAPA 和(hé)仿(fǎng)真(zhēn)与(yǔ)现(xiàn)实(shí)协(xié)同(tóng)训(xun)练(liàn)技(jì)术(shù)。通(tōng)过(guò)整(zhěng)合(hé)这(zhè)些(xiē)创(chuàng)新(xīn)成(chéng)果(guǒ),GR00T N1 不(bù)仅(jǐn)能(néng)够(gòu)遵(zūn)循(xún)指(zhǐ)令(lìng)、执(zhí)行(xíng)任(rèn)务(wu),更(gèng)在(zài)复(fù)杂(zá)且(qiě)不(bù)断(duàn)变化的环境中,为通用人形机器人的能力设立了新标杆。
GR00T N1.5 是基于 GR00T N1 升级的通用人形机器人开源基础模型,其特点是采用了经过优化的视觉语言模型,该模型训练数据包括真实数据、仿真数据和 DreamGen 生成的合成数据的多样化组合。
通过架构优化与数据质量提升,GR00T N1.5 实现了三大核心突破:提升任务成功率、增强语言理解能力、增强对新物体与任务的泛化能力,从而成为更稳定可靠、适应性更强的先进机器人操作解决方案。
通过视频进行潜在动作预训练
通过视频进行潜在动作预训练 (LAPA) 是一种用于视觉-语言-动作 (VLA) 模型预训练的无监督方法,无需使用成本高昂且需人工标注的机器人动作数据。LAPA 不依赖大规模带标注的数据集,这类数据集的收集既昂贵又耗时,而是利用超过 181,000 个未标注的互联网视频来学习有效的特征表示。
这种方法在真实世界任务中,相比先进模型实现了 6.22% 的性能提升,且预训练效率提高了 30 倍以上,这使得具备可扩展性(xìng)和(hé)稳(wěn)健(jiàn)性(xìng)的(de)机(jī)器(qì)人(rén)学(xué)习(xí)变(biàn)得(de)更(gèng)加(jiā)便(biàn)捷(jié)高(gāo)效(xiào)。
LAPA 工(gōng)作(zuò)流(liú)分(fēn)为(wèi)三(sān)个(gè)阶(jiē)段(duàn):
潜(qián)在(zài)动(dòng)作(zuò)量(liàng)化(huà):Vector Quantized Variational AutoEncoder (VQ-VAE) 模(mó)型(xíng)通(tōng)过(guò)分(fēn)析(xī)视(shì)频(pín)帧(zhèng)之(zhī)间(jiān)的(de)转(zhuǎn)换(huàn),学(xué)习(xí)离(lí)散(sàn)的(de)“潜(qián)在(zài)动(dòng)作(zuò)”,从(cóng)而(ér)构(gòu)建(jiàn)一(yī)套(tào)基(jī)础(chǔ)行(xíng)为(wèi)词汇(huì)(例(lì)如(rú)抓(zhuā)取(qǔ)、倾(qīng)倒(dào))。潜(qián)在(zài)动(dòng)作(zuò)是(shì)低(dī)维(wéi)度(dù)的(de)习(xí)得(de)表(biǎo)征(zhēng),可(kě)概(gài)括(kuò)复(fù)杂(zá)的(de)机(jī)器(qì)人(rén)行(xíng)为(wèi)或(huò)运(yùn)动(dòng),便于对高维度动作进行控制或模仿。
潜在预训练:利用行为克隆对 VLM 进行预训练,使其能基于视频观察结果和语言指令,预测第一阶段得到的这些潜在动作。行为克隆是一种模型学习方法,通过将观察结果映射到动作,利用演示数据中的示例来复制或模仿动作。
机器人后训练:之后,使用小型带标签数据集对预训练模型进行后训练,使其适配实体机器人,将潜在动作映射为物理指令。
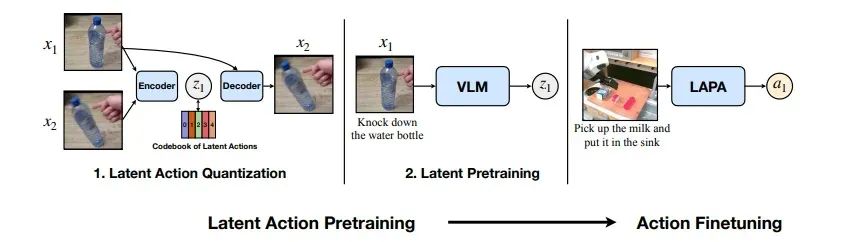
图 4. 潜在动作预训练概览
仿真与现实协同训练工作流
机器人策略训练面临两大关键挑战:一是收集真实世界数据的成本高昂;二是存在“现实差距”,仅在仿真环境中训练的策略,往往难以在真实物理环境中良好运行。
仿真与现实协同训练工作将少量真实世界机器人演示数据与大量仿真数据相结合,有效解决了这些问题。这种方法能够训练出鲁棒策略,同时有效降低成本并弥合现实差距。
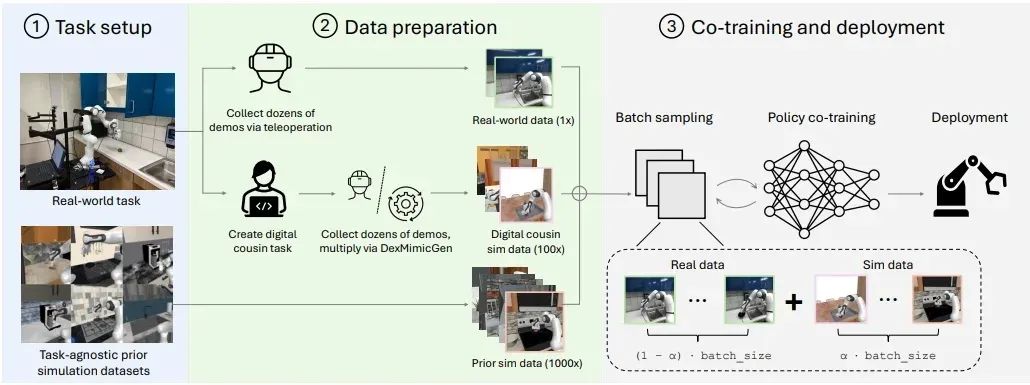
图 5.仿真与现实协同训练工作流概览
该工作流的关键步骤如下:
任务与场景设置:搭建真实世界任务场景,并选择与任务无关的先验仿真数据集。
数据准备:在数据准备阶段,从实体机器人收集真实世界演示数据,同时生成额外的仿真演示数据。这些仿真数据既包括与真实任务高度匹配的、具有任务针对性的“digital cousins”数据,也包括多样化的、与任务无关的先验仿真数据。
协同训练参数调优:随后,将这些不同来源的数据按优化后的协同训练比例进行融合,重点在于对齐摄像头视角并最大化仿真数据的多样性(而非追求照片级真实感)。最后阶段包括批量采样,以及利用真实数据和仿真数据进行策略协同训练,最终得到可部署在机器人上的稳健策略。

图 6. 仿真与现实任务对比示意图
如图 7 所示,增加真实演示数据的数量,能提升仅使用真实数据训练策略,以及经过协同训练策略的成功率。即使使用 400 组真实演示数据,协同训练策略的表现仍始终优于仅用真实数据训练的策略,平均提升幅度达 38%。这表明,即便在数据充足的场景中,仿真与现实协同训练依然能带来显著成效。
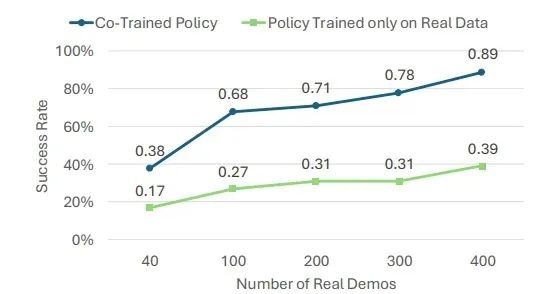
图(tú) 7. 协(xié)同(tóng)训(xun)练(liàn)策(cè)略(è)与(yǔ)纯(chún)真(zhēn)实(shí)数(shù)据(jù)策(cè)略(è)性(xìng)能(néng)对(duì)比(bǐ)图(tú)
生(shēng)态(tài)系(xì)统(tǒng)应(yīng)用(yòng)
领(lǐng)先(xiān)的(de)机(jī)器(qì)人(rén)公(gōng)司(sī)正(zhèng)在(zài)采用(yòng) NVIDIA 研(yán)究(jiū)中(zhōng)心(xīn)开(kāi)发(fā)的(de)工(gōng)作(zuò)流(liú)来(lái)加(jiā)速(sù)研(yán)发(fā)进(jìn)程(chéng)。GR00T N 系(xì)列(liè)模(mó)型(xíng)的(de)早(zǎo)期(qī)采用(yòng)者(zhě)包(bāo)括(kuò):
AeiRobot:应(yīng)用(yòng)该(gāi)模(mó)型(xíng)使(shǐ)工(gōng)业(yè)机(jī)器(qì)人(rén)能(néng)够(gòu)理(lǐ)解(jiě)自(zì)然(rán)语(yǔ)言(yán)指(zhǐ)令(lìng),完(wán)成(chéng)复(fù)杂(zá)分(fēn)拣(jiǎn)放(fàng)置(zhì)任(rèn)务(wu)。
Foxlink:利(lì)用(yòng)模(mó)型(xíng)提(tí)升(shēng)工(gōng)业(yè)机(jī)械(xiè)臂(bì)的(de)作(zuò)业(yè)灵(líng)活(huó)性(xìng)与(yǔ)操(cāo)作(zuò)效(xiào)率(lǜ)。
光(guāng)轮(lún)智(zhì)能(néng):通(tōng)过(guò)模(mó)型(xíng)验(yàn)证(zhèng)合(hé)成(chéng)数(shù)据(jù),加(jiā)速(sù)人(rén)形(xíng)机(jī)器(qì)人(rén)在(zài)工(gōng)厂(chǎng)场(chǎng)景(jǐng)的(de)部(bù)署(shǔ)进(jìn)程(chéng)。
NEURA Robotics:评(píng)估(gū)模(mó)型(xíng)性(xìng)能(néng)以(yǐ)加(jiā)速(sù)家(jiā)庭(tíng)自(zì)动(dòng)化(huà)系(xì)统(tǒng)的(de)研(yán)发(fā)。
ONLINE MESSAGE
在线留言
*注:请务必信息填写准确,并保持通讯畅通,我们会尽快与你取得联系


上海智能机器人科技股份有限公司
Shanghai United Intelligence Robotics Inc.
产品咨询: sale@jinnian.com
其他业务: service@jinnian.com
销售热线:400-65738829-8071
邮寄地址:上海市浦东新区申迪南路80号5楼
一 子公司 一
智能机器人(浙江)有限公司
United Intelligence Robotics (Zhejiang) Co.,Ltd
电子邮箱: e-mail@jinnian.com
业务咨询: contact@jinnian.com
销售热线:0755-25836555
万维网址: www.ybgsyj.com
邮寄地址: 浙江省杭州市滨江区长河街道网商路586号6幢3层

扫码手机查看